Timeouts and HTTP Connection Reuse
When building an application which talks to some dependencies over the network it's generally recommended to always specify timeouts1. This prevents resources (threads, connections, descriptors) from being occupied for a long time - worst case indefinitely2 - when a dependency becomes slow or unavailable, which could manifest as an application being slow or appear to stuck. Timeouts also allow to retry by contacting a different server instead of waiting for a response from a struggling server that might never arrive.
Timeouts can be configured for different stages: establishing a connection, whole request-response cycle, waiting for the response, or individual IO operations. Connection timeouts can be safely retried and are relatively straightforward to reason about. Hitting a timeout when performing a request are more tricky as they can result in an unusable connection that has to be closed. Let's look at the details to understand why exactly is this the case. I'll use HTTP as an example, but the same issues arise when working with other protocols.
Let's look at HTTP/1.1 first before exploring how HTTP/2 and HTTP/3 improve upon it. The underlying transport protocol used is TCP. A TCP connection is a bidirectional stream. It can be thought of as a pair of channels, one for sending data (request) and one for receiving (responses), each a sequence of bytes delivered reliably and in-order. Programs interact with a connection represented as a socket (an operating system API) that can be written to (send()) and read from (recv())3.
To avoid paying the latency cost of establishing a connection for each request a connection is reused to send/receive multiple requests/responses (messages). A pool of connections is typically maintained to perform more than one request concurrently. There're two most common approaches for distinguishing messages sent over the same socket from one another: delimiters and length-prefixing4. With delimiters a sequence of bytes is acting as a separator (e.g. a newline separates HTTP message headers from message body or the next message). With length-prefixing the size of the payload is specified at the beginning of the message (HTTP Content-Length is a variation of this approach; chunked encoding5).
Depending when timeout occurs in the request-response exchange the connection is left in a different state. First the request data is queued up for transmission by handing it over to the OS kernel using send(), which might be accepted in chunks, requiring multiple function calls. At this point we don't know yet if the data was actually sent out or delivered6, reflecting asynchronous nature of the network. In some cases (when the network is congested or the server is overloaded) a timeout might occur before all request data was queued up. A connection in this state cannot be used to send a retry or any other request, as this would lead to data corruption due to broken message boundaries.
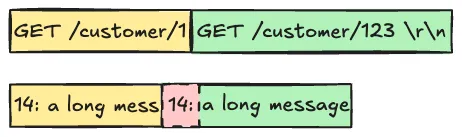
Most often a timeout occurs when waiting for a response or a part of the response to arrive. If reading of the remaining data from the socket is abandoned, the next read will receive the tail of the previous message when expecting a beginning of the next message.
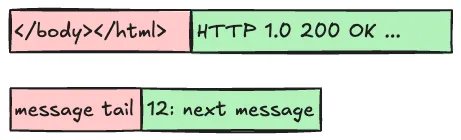
Given TCP guarantees that data will eventually delivered and delivered in order, it's theoretically possible to avoid corruption by making sure requests/responses are always sent/received completely, even after timeout occurs. This however would increase complexity and forces both the server and the client to do additional work only to throw the results away. Also there's no guarantee that it would be possible to recover a connection, potentially already abandoned by the server - the process would need its own timeout. And finally HTTP allows message bodies without a predetermined length (chunked) and responses that last long as the connection is open7. In practice HTTP clients side step these issues altogether by having a blanket policy to close a connection on a timeout, as well as on an IO error sending/receiving data.
As establishing a new connection introduces an additional delay compared to a typical request-response time, especially if TLS is used on top to protect the data in-flight - 2 RTT for HTTP before version 3 and CPU intensive cryptographic work for the server. Pooling is helpful to amortize the cost of establishing a connection, and allows them to be opened ahead of time are kept open when not in use. Pooling will only help if there're free connections available - a sequence of retries, especially happening across multiple concurrent requests, can quickly lead to replacing all the connections. Reestablishing multiple connections all at once, potentially from many clients, when the server is already struggling with load would not help. Therefore you probably don't want too tight timeouts and too eager retries. Timeouts should be rather rare and not something that happens regularly in response to every variation in response latency.
HTTP/2 introduces stream multiplexing over a single TCP connection: messages are not sent sequentially but are broken down into interleaved frames, each belonging to a stream. Length-prefixed frames within each stream are processed sequentially and are reassembled into HTTP request/response messages by the receivers. Streams can be closed without terminating the underlying connection. A timeout in the middle of sending/receiving a message would require closing of the corresponding stream, but only a partially written/received frame would make the whole TCP connection unusable. As each frame has a known size, it's also easier to bring a connection to a safe state after a timeout by finishing reading/writing of the frame before resetting the stream compared to HTTP/1.x.
HTTP/3 is similar to HTTP/2 in that it multiplexes streams over a single underlying transport connection. A significant different is that the underlying transport protocol is QUIC and not TCP. QUIC itself provides multiplexing - a stream for each HTTP/3 request/response pair. Even if an HTTP/3 frame is written to a QUIC stream partially it doesn't affect the other streams and the underlying connection8. QUIC achieves this by delivering each packet within a single UDP datagrams, which are transferred between a program and the OS kernel as a single piece of data9. Reading from a UDP socket (recvmsg()) will yield a complete QUIC frame. On top of UDP QUIC cryptographically ensures packet integrity by integrating TLS.
To sum it up, client timeouts are important for resource utilization and resiliency. With a stream-oriented transport protocol such as TCP, timeout can break message framing due to partial reads/writes that prevents connection reuse to avoid data corruption. This affects application protocols such as HTTP/1.x and HTTP/2. A typical client implementation will close the connection whenever a timeout occurs. Too tight request timeouts can negatively impact latency and cause connection pool exhaustion. HTTP/3 is based on QUIC instead of TCP which addresses these issues by building on UDP, a message oriented protocol. This allows to maintain framing for concurrent independent streams within the same connection, even in face of partially sent/received message.
An unfortunate common default is no timeout. Python's http module will use the socket default of no timeout. Go's http package defaults to zero timeouts, which means no timeout.↩
Stevens, W. Richard. 2003. Unix Network Programming. 3rd edition↩
See Linux
send()/recv()and the Windows API↩Mark Teisman. TCP Message Protocols. https://www.markteisman.com/blog/message-protocols-for-tcp/↩
While TCP provides acknowledgements to track how much data was delivered, this information is not easily available to applications directly, requiring an explicit response. Successful delivery of data over the network doesn't mean that it was actually processed by the receiving node.↩
HTTP/3 also reduces the cost of (re-)establishing a connection.↩
recvmsg(3p), sendmsg(3) Linux manual pages↩